ProRoc: products of experts for robotic manipulation.
POLONEZ BIS-1 project financed by the National Science Centre (NCN)

-
Principal Investigator (fellow): dr Marek Kopicki, e-mail: marek.kopicki(at)put.poznan.pl, tel: +48 616652809
Investigators: dr Sainul Ansary, Jakub Chudziński, Piotr Michałek
Mentor: prof dr hab. inż. Piotr Skrzypczyński
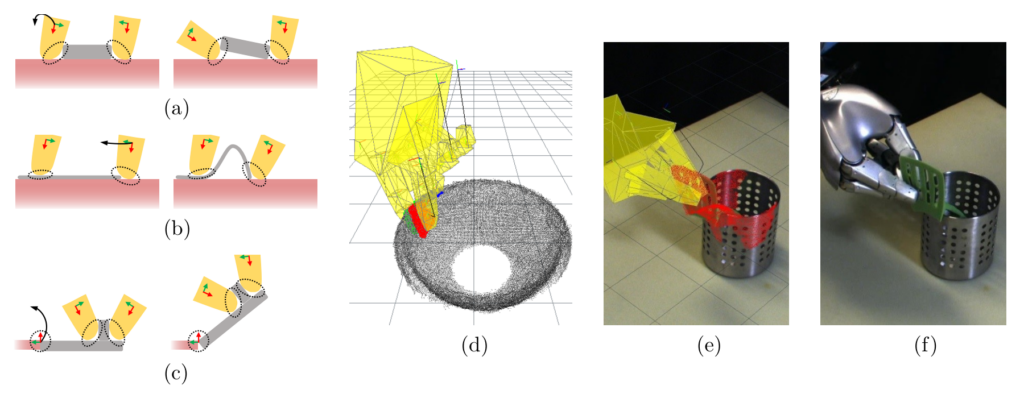
Examples of manipulation scenarios (a-c) In columns: grasping a low rigid object (a) or a sheet of paper/cloth (b), from a table/flat surface/another object; opening a door (c). Point-based contact models (d-f): demonstration of point-based feature contacts, one per each robot link (d), transfer of contacts to a novel point cloud and performed grasp (e, f).
Autonomous robotic manipulation in novel situations is widely considered as an unsolved problem. Solving it would have enormous impact on society and economy. It would enable robots to help humans in factories, warehouses, but also at homes in everyday tasks.
This project will advance the state of the art in learning algorithms which will enable a robot to autonomously perform complex dexterous manipulation in unfamiliar situations in the real-world with novel objects and significant occlusions. In particular to grasp, push or pull rigid objects, but also to some extent, non-rigid and articulated objects that can be found at homes or in warehouses. Importantly, similarly to humans, a robot will also be able to envision results of its actions, without actually performing them. A robot could plan its actions, e.g. to tilt a low object to be able to grasp it, to bend a cloth before gripping and then pulling, to slide a sheet of paper to the edge of a table, or to open a door.
End-to-end/black-box approaches have made it possible to learn some of these kinds of complex tasks with almost no prior knowledge, for example by learning RGB image to motor command mapping directly. While this is impressive, typically the end-to-end manipulation learning requires prohibitive amounts of training data, scales poorly to different tasks, does not involve prediction and struggles to provide interpretation of its behaviour, why the learned skill fails. On the other hand, it was shown that exploiting the problem structure can help learning. For example, in bin picking scenarios, many successful approaches assume at least depth images or trajectory planners for robot control. In autonomous driving, adding representations such as depth estimation, or semantic scene segmentation enable to achieve the highest task performance.
We proposed a modularisation of the learned task, which opens up black-boxes and make them explainable. We introduced a first algorithm that was capable to learn dexterous grasps of novel objects from just one demonstration. It models grasps as a product of independent experts – object-hand link contact generative models, which accelerates learning and provides a flexible problem structure. Each model is a density over possible SE(3) poses of a particular robotic link, trained from one or more demonstrations. Grasps can be selected according to the maximum likelihood of a product of involved contact models, and their relative poses controlled by manifolds in hand posture. Furthermore, we introduced an algorithm which can learn accurate kinematic predictions in pushing and grasping solely from experience, without any knowledge of physics. However, our current algorithms and models either do not involve prediction (in grasping), they are insensitive to task context and prone to occlusions, or they assume object exemplars (in prediction). In this project, we will overcome all these limitations, by introducing hierarchical models which rely on CNN features, and which can represent both visible and occluded parts of objects of both hand link-object and object-object contacts, and also the entire manipulation context. The CNN can be trained offline, while our hierarchical models can be efficiently trained during demonstration. Furthermore, we will enable learning the quantitative generative models of SE(3) motion of objects for grasping, pushing and pulling actions. They can be trained from demonstration and experience from depth and RGB images, all within the same one algorithm. Finally, we will attempt to model dynamical properties of contacts, and learn from experience a maximum resistible wrench, a maximum wrench that does not break hand-object contact. It would enable prediction of slippage for a given hand-object contact for pushing, pulling and grasping.
-
NN architectures for contact models
we investigate architectures for building new generation of contact models with help of NN. Contact models are learned from demonstration with simple memory-based training. We propose to reconstruct a full object model with hidden/occluded surfaces as a point cloud using our new approach DepthDeepSDF, and then to create contact models that relies on the complete robot-object set of contacts. We expect that this will increase robustness of grasps, by decreasing likelihood of predicting invalid contacts due to collisions with invisible parts, or contacts that are “floating in space”.

DepthDeepSDF performs the normalisation directly in the depth image “space”, with (x, y) image coordinates, and a depth coordinate (z) along a “depth” projection ray of the pinhole camera model.

DeepSDF vs DepthDeepSDF performance comparison for bottle category (distance values – the smaller, the better). Right: example grasp performed by Franka robotic arm with the 2-finger gripper.
Preliminary results of 3D reconstruction of occluded scene and objects’ parts are published and presented in ”3D Object Reconstruction from a Single Depth View – Comparative Study” (proc. PP-RAI 2023).
Prediction learning
We investigate ways of encoding relative object and hand motions, given constraints introduced by contact models. Here, we are particularly interested in underactuated robots rather than in fully actuated robots, because they are potentially stronger, more reliable, and more robust in terms of adapting to the object shapes. They also conceptualise the difficulty of learning manipulation in terms of the uncertainty of the manipulation results.

The object can start moving depending on the complexity of the object and gripper fingers’ dynamics. Still, our approach enables contact learning and planning leading to successful grasps (Figure far right).
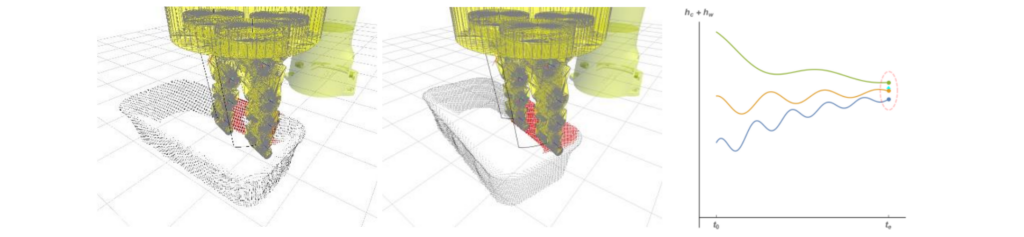
The example grasp trajectory begins with the initial set of contacts (Left, visualised as a region in red colour), and leads to the equilibrium state and contacts (Middle). In general, apparently complex dynamics/trajectories often lead to a similar equilibrium state (Right, at time tc).
During manipulation with underactuated robotic gripper, motion of fingers with respect to the target object cannot be fully controlled, consequently the object may significantly move. We proposed to learn trajectories leading to the equilibrium state, but in the course of further experiments it turned out that for a given set of object-gripper contacts the movement of the manipulated object is predictable as a relatively unimodal set of SE(3) displacements, but also that the importance of the contact quality estimated during training.
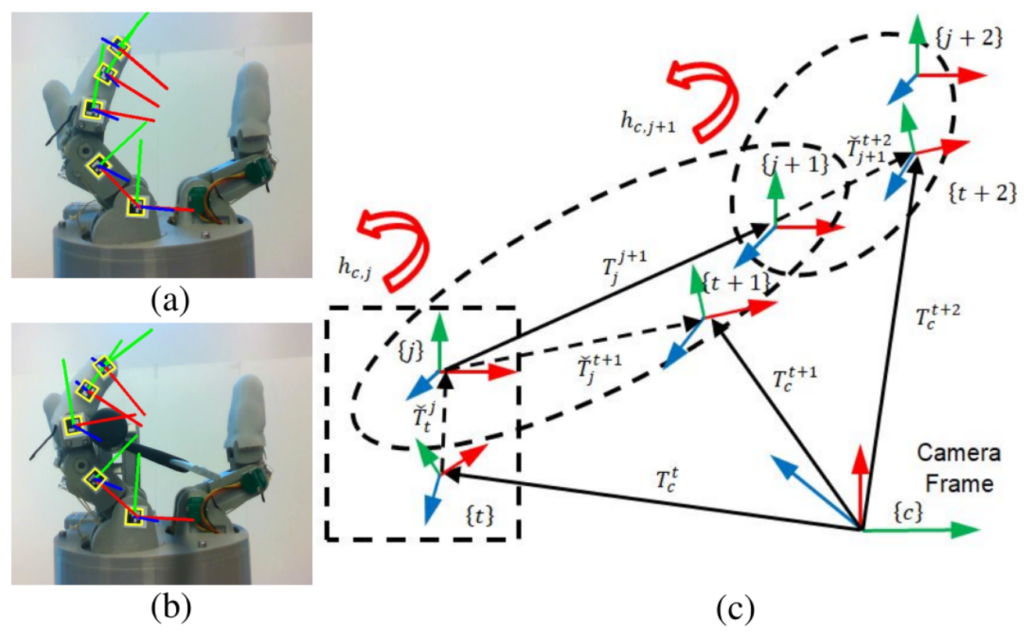
Sensor model estimation without(a) and with(b) obstacle, kinematic relation between frames(c).
We have used Sensor Model to estimate actual joint configuration of our underactuated robotic gripper, by estimating from examples parameters of our model in both: free-space movements and when fingers touches the obstacle. The model estimates joint positions that have no encoders, from proximal joint encoders and from motor position readings.
Sensor model estimation without(a) and with(b) obstacle, kinematic relation between frames(c).
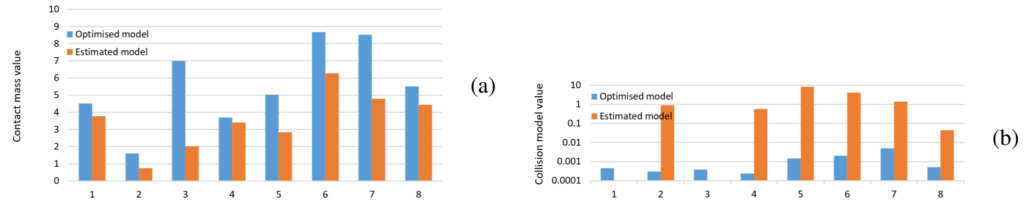
We also applied Kinaesthetic Contact Optimisation procedure (KCO). Due to sensor model limitations and imperfect camera calibration, some contact models were not created because the target object was too far away, or there were created, but colliding with the object. KCO adjusts gripper joint configuration and its 3D pose w.r.t. the training object, minimising collision model value while maximising link-object contacts locally (contact mass value), in some neighbourhood of a training grasp example.
Manipulation learning
We demonstrate a robotic system that combines the algorithms developed during the project, but also our RP-joint mechanism. While RP-joints significantly improve gripper dexterity, by design they require external forces to reconfigure. Those forces can be generated by the robot itself by pushing its fingers against an obstacle. Our autonomous planner creates a sequence of trajectories that re-configure the gripper as desired before manipulating the object.

To reconfigure 2 RP-joints from 0° to 90°, our planner creates a sequence of 6 trajectories.
The robot was demonstrated with 8 training trajectories, each labelled 1 to 8, all on 6 IKEA objects.

Grasp training examples.
For tests we used 42 IKEA objects at semi-random poses on the table, creating in this way 128 object-pose pairs for grasping. We compared both models – with Kinaesthetic Contact Optimisation and without, each time replicating exactly the same object-pose pair, but capturing the test point clouds independently. The robot performed a total of 256 grasp trials fully autonomously. Optimized models performed with 80% success rate, significantly better than contact models without optimisation, with a success rate of 57%. We further validated our algorithm with optimized models on the YCB dataset, with a success rate of 87% on 120 grasps and 8 objects at various poses.

Example grasps of objects from IKEA dataset.
More in the video for our paper „Underactuated dexterous robotic grasping with reconfigurable passive joints”.
Underactuated dexterous robotic grasping with reconfigurable passive joints.
RP-joints
We introduced a novel reconfigurable passive joint (RP-joint). The proposed mechanism can provide extra degrees of freedom to the gripper without employing any direct actuators. RP-joint has no actuation, but instead it is lightweight and compact. It can be easily reconfigured by applying external forces and locked to perform complex dexterous manipulation tasks, but only after tension is applied to the connected tendon.
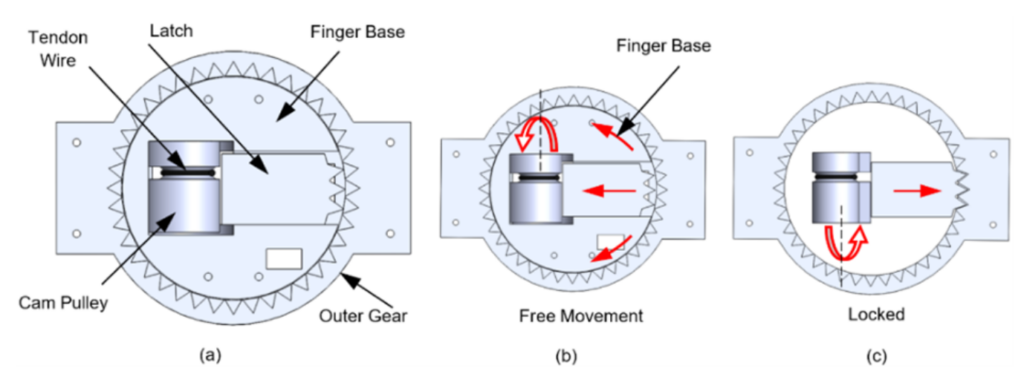
The working principles of the RP-joint mechanism.
Three-finger underactuated robotic gripper with RP-joints
Our RP-joint mechanism has been implemented and tested on an underactuated three-finger robotic gripper. The gripper consists of three identical fingers placed on a palm-base symmetrically 120° apart from each other. RP-joints allow the fingers to spread sideways freely during pre-grasp gripper configuration and lock itself during grasping. The proposed mechanism provides two extra degrees of freedom to the gripper without employing any direct actuators.
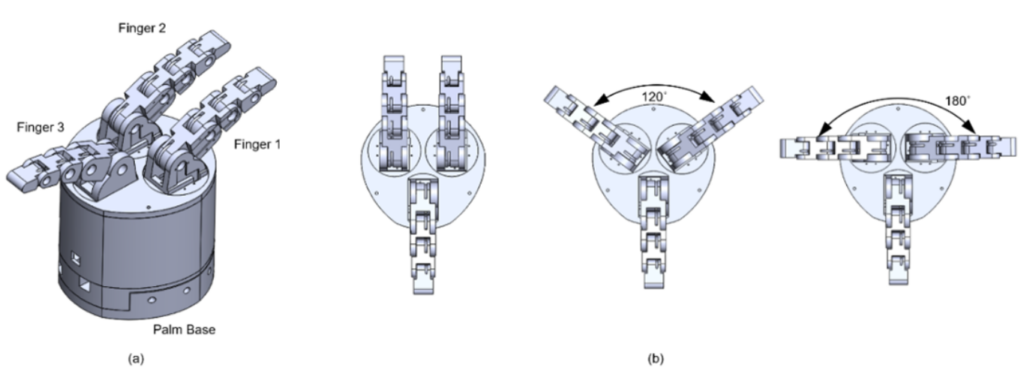
Three-finger underactuated robotic gripper and its different configurations.
Each finger has five links connected by two types of joints – active and passive. The active joints are directly controlled by actuators. Here, tendon wires are used to transfer power from actuators to the active joints. A single tendon wire in each finger running over the joint pulleys, transfers actuation power from a servo actuator situated inside the palm-base. The tendon wires only provide flexion motion to the fingers, while linear extension springs at each joint provide extension motion.
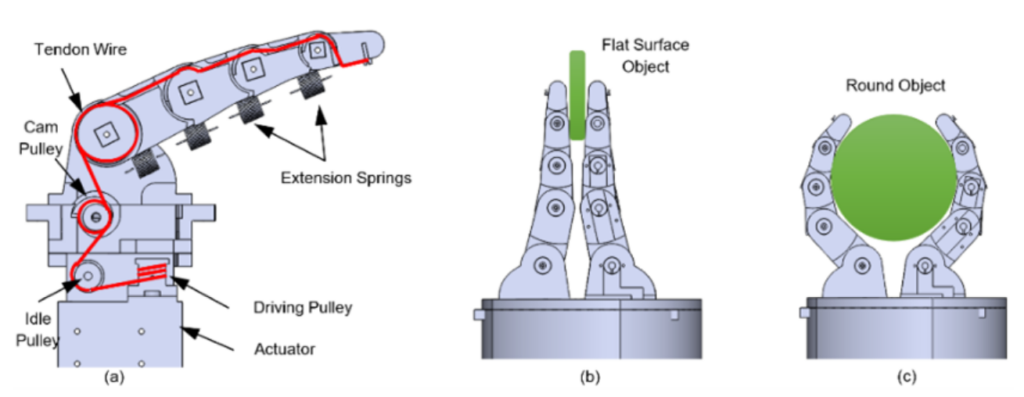
(a) tendon routing inside finger, (b) fingertip type of grasps, (c) enveloping type of grasps.
-
Events
- Meeting with business advisors from Poznań Science and Technology Park to discuss potential commercial applications and sources of financing for ideas developed within the project, 2024.
- Invited talk at Technical University of Darmstadt, Germany, 2024.
- Presented posters at PP-RAI 2023 in Łódź and at PP-RAI 2024 in Warsaw, Poland.
- Invited speaker at ERF 2023 European Robotics Forum in Odense, Denmark, 2023.
- Invited speaker at 2nd International Roboticist Forum in Schweinfurt, Germany, 2023.
- Keynote speaker during visit of representatives from Bavarian Universities in Poznań, Poland, 2023.
- Invited speaker at the meeting with the representatives of Volkswagen Poznań devoted to the prospects for future cooperation, 2023.
- Seminar of the Robotics Division at IRIM, Poznań, Poland, 2023.
Publications
- M. Kopicki, S. I. Ansary, S. Tolomei, F. Angelini, M. Garabini and P. Skrzypczyński, „Underactuated Dexterous Robotic Grasping With Reconfigurable Passive Joints,” in IEEE Robotics and Automation Letters, vol. 10, no. 1, pp. 48-55, Jan. 2025, doi: 10.1109/LRA.2024.3497714.
- M. Kopicki, S. I. Ansary, “A joint for movably connecting two members”, pat. WIPO ST 10/C PL450216, 2024.
- Staszak R., Michałek P., Chudziński J., Kopicki M., Belter D., 3D Reconstruction of Non-Visible Surfaces of Objects from a Single Depth View – Comparative Study. W: Progress in Polish Artificial Intelligence Research 4, Wojciechowski A. (Ed.), Lipiński P. (Ed.)., Seria: Monografie Politechniki Łódzkiej Nr. 2437, Wydawnictwo Politechniki Łódzkiej, Łódź 2023, s. 19-24, ISBN 978-83-66741-92-8, doi: 10.34658/9788366741928.1.



This research is part of the project No 2021/43/P/ST6/01921 co-funded by the National Science Centre and the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No 945339.
This project is affiliated at the Robotics Division, Institute of Robotics and Machine Intelligence (IRIM) at Poznan University of Technology.
IRIM specializes in AI-based robotics, computer vision, and embedded systems. Over the past five years, they have published more than 50 papers in top conferences and journals, and hold over 10 patents in computer vision and robotics. They collaborate with industry partners on R&D projects, including autonomous legged robots and industrial manipulation systems. Their research focuses on autonomous systems, perception-based decision making, and advanced manipulation techniques.